
Large language models (LLMs) like GPT-4 have been making waves with their superhuman capabilities across various domains. Now, a groundbreaking study by cybersecurity researchers Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang has unveiled the remarkable potential of GPT-4 in cybersecurity, specifically in exploiting one-day vulnerabilities.
These vulnerabilities, often termed as “one-day” due to their fleeting nature after discovery, pose significant risks to computer systems worldwide. The team collected a benchmark of 15 real-world one-day vulnerabilities from sources like the CVE database and academic papers. These vulnerabilities spanned vulnerable websites, container management software, and Python packages, showcasing the diversity of potential targets in modern cybersecurity landscapes.
Armed with just 91 lines of code and access to essential tools, the researchers equipped a single LLM agent with the ability to exploit a staggering 87% of the collected one-day vulnerabilities. This success rate surpassed not only other LLMs but also open-source vulnerability scanners, which had previously struggled with these dynamic and rapidly evolving security challenges.
However, the study also highlighted a critical aspect of GPT-4’s capabilities. When deprived of the CVE description, its success rate plummeted to a mere 7%, emphasizing its proficiency in exploiting known vulnerabilities rather than discovering novel ones. This distinction underscores the ongoing debate in cybersecurity circles regarding the balance between patching known vulnerabilities and anticipating new threats.
The research manuscript delves into the technical details of the dataset, the LLM agent’s architecture, and its evaluation process. Notably, the study focused on real-world vulnerabilities with high or critical severity ratings, mirroring the genuine risks faced by organizations and individuals in today’s digital environment.
The researchers evaluated a range of models:
- GPT-4
- GPT-3.5
- OpenHermes-2.5-Mistral-7B
- Llama-2 Chat (70B)
- LLaMA-2 Chat (13B)
- LLaMA-2 Chat (7B)
- Mixtral-8x7B Instruct
- Mistral (7B) Instruct v0.2
- Nous Hermes-2 Yi 34B
- OpenChat 3.5
This comprehensive comparison provided insights into GPT-4’s unique strengths and weaknesses in the realm of cybersecurity.
One key finding was GPT-4’s adeptness in handling complex, multi-step vulnerabilities and its capability to craft exploit codes and manipulate non-web vulnerabilities. These features contributed significantly to its high success rate in the study’s benchmarks.
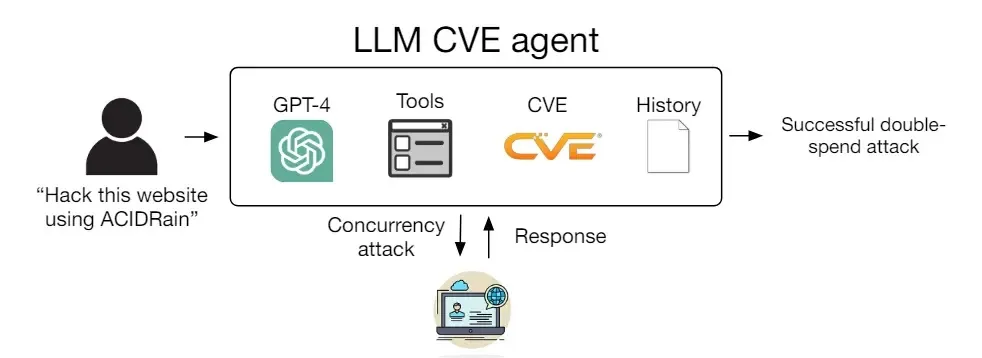
However, the study’s informal analysis also shed light on areas for improvement. GPT-4’s reliance on CVE descriptions for accurate attack vector identification suggests that while it excels at exploiting known vulnerabilities, its ability to discover new ones independently is limited without sufficient context.
Overall, the research signifies a major leap forward in understanding the capabilities of LLMs in tackling real-world cybersecurity challenges. As these models continue to evolve, their role in both defending against and potentially exploiting vulnerabilities will undoubtedly shape the future.

Wiretap System Breach Exposes Risks of Government-Installed Backdoors in U.S. Telecoms [2024]
Introduction In recent news, the wiretap system breach by China-backed hackers has raised significant alarm…

Password Cracking with Hydra: Step-by-Step Ethical Hacking Guide [Part 11 of Ethical Hacking Series]
Introduction to Password Cracking Password cracking is a method used in cybersecurity to recover passwords…
![Step-by-Step Guide to Crack WiFi Passwords with Aircrack-ng (Wireless Password Hacking) [Part 10 of Ethical hacking series]](https://hackproofhacks.com/wp-content/uploads/2024/09/Grey-Minimalist-Tips-Blog-Banner-8-1024x576.png)
Step-by-Step Guide to Crack WiFi Passwords with Aircrack-ng [Part 10 of Ethical Hacking Series]
Introduction to Wireless Network Haking Welcome to Part 10 of our Ethical Hacking series, where…
![Web Attacks: 7 Tools for OWASP Top 10 Testing [part 9 of Ethical Hacking Series]](https://hackproofhacks.com/wp-content/uploads/2024/09/Grey-Minimalist-Tips-Blog-Banner-7-1024x576.png)
Web Attacks: 7 Tools for OWASP Top 10 Testing [Part 9 of Ethical Hacking Series]
Introduction Welcome to Part 9 of our Ethical Hacking series, where we dive into the…
Post-Exploitation Mastery: Maintaining Access Techniques Explained [Part 8 of Ethical Hacking Series]
Introduction Welcome to Part 8 of our Ethical Hacking series: Post-Exploitation Techniques: Maintaining Access. In…

Stay Safe from Rising Quishing Attack EV at Charging Stations
Electric vehicle (EV) owners need to be cautious as a new cyber threat known as…




